 Darren Pinder
Darren PinderAt Vatu Ltd, we have 3 main goals: Create high-quality websites Give great customer service to our clients Create a happy, safe,...
Create a Slack Bot for RSS Feeds
 thewongguy
thewongguy
Abstract
The goal of this project was to create a Slack Bot which would post blog updates into our Slack. This was born in part, due to laziness. I did not want to manually check for new posts and I had reached the RSS feed limit in my reader. I also wanted to learn AWS Lambda, S3, and the AWS SDK, boto3. I should note, this functionality exists in Slack.
It is recommended to install Python 3.6.1 as that is what AWS Lambda is currently using, as well as using a virtual environment. Follow these instructions to set it up.
High Level Overview
- Check for Last Update
- Check for Title, Url, and Username
- Store Last Modified Date and Title
- Compare Last Modified Date Against Stored Date
- Retrieve New Posts and Update Date and Title
- Post to Slack
Check for Last Update
My initial thought was to check the blog using requests to store the page, repeat on a schedule, and compare if there were any differences. This is a bit of an expensive call as it would be downloading the page each and every time.
My next thought, I had gotten some inspiration from Reddit. You could do an inexpensive HEAD request and read the headers for last modified.
My third thought, does this have a RSS feed? It would be best to test against that to avoid false positives if the site had updated some content such as a logo update. Let’s check the RSS feed’s header.
Be sure you have requests installed by doing:
pip install requests>>> import requests
>>> def get_last_modified(url):
... return requests.head(url).headers['Last-Modified']
...
>>> print(get_last_modified('https://rocketsquirrel.org/feed'))
Fri, 01 Sep 2017 15:08:57 GMT
>>>Check for Title, Url, and Username
Use RSS feed parser library, feedparser, to get blog entry details for title and url.
Initially, I used the feedparser library to get the author, but I ran into an issue where it would get the author’s full name instead of the Slack username.
Instead, let’s get the Slack username by searching the url for the first ‘@’ character up until the next ‘/’ character in the blog post’s url.
Make sure you have feedparser installed by doing:
pip install feedparser>>> import feedparser
>>> def get_posts(url):
... feed = feedparser.parse(url)
... for item in feed.entries:
... print(item.title)
... print(item.link)
... print(item.link[item.link.index('@'):item.link.index('/', item.link.index('@'))])
...
>>> get_posts('https://rocketsquirrel.org/feed')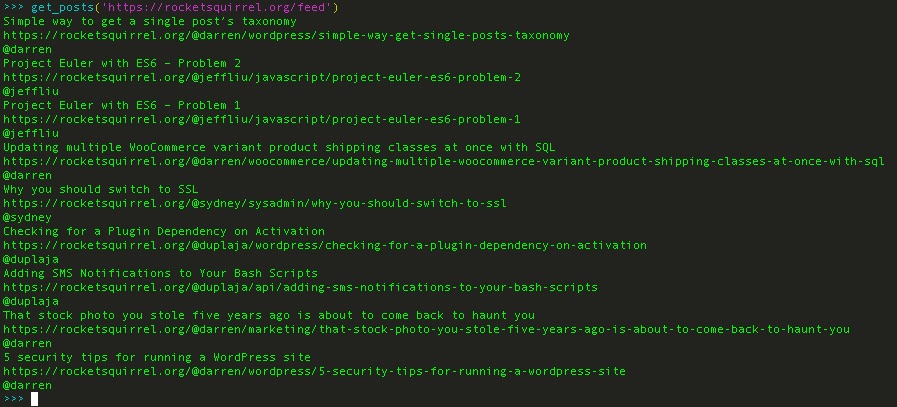
Store Last Modified Date and Title
The stored date and title will represent the most recent blog entry we posted to Slack and its modified timestamp.
We will use this to compare whether the blog has been updated and to retrieve the latest blog entries.
There were a few ways to store the data. I choose not to go with a file on the filesystem, as I wanted to go serverless with AWS Lambda. Nor did I go with a database as I did not need to maintain historical data. Plus it did not seem cost effective keeping a database running and doing barely any writes. Instead, I choose to post to S3 a small json file. This seemed the most cost effective way forward with little overhead.
AWS Setup
Setup IAM roles and S3 bucket
Create Group
- Go to IAM services in your AWS console
- Groups > Create New Group
- Choose an unique group name such as ‘s3group’ > Next Step
- Attach the policy ‘AmazonS3FullAccess’ to the group > Next Step > Create Group
Create User
- Go to IAM services in your AWS console
- Users > Add Users
- Choose an unique user name such as ‘s3user’
- Select the checkbox for Programmatic access > Next: Permissions
- Select the group you created earlier with AmazonS3FullAccess
- Next: Review > Create User
- Note down your Access key ID and Secret access key
Create S3 Bucket
- Go to S3 in your AWS console
- + Create bucket
- Enter an unique Bucket name and select your preferred Region
- Next > Set your preferred properties
- Next > Set your preferred permissions
- Next > Create bucket
Code
Make sure you have boto3 installed by doing:
pip install boto3Update your bucket with the name you choose earlier
Note: I had defined my AWS tokens as variables before hand
Note: You will be passing the last update time and blog post title from prior steps
>>> import boto3
>>> import json
>>> def write_to_s3(access_key_id, secret_access_key, date, title):
... client = boto3.client('s3',
... aws_access_key_id=access_key_id,
... aws_secret_access_key=secret_access_key)
... body = {'date': date, 'title': title}
... json_body = json.dumps(body)
... client.put_object(ACL='private',
... Bucket='rocketsquirrel',
... Key='rocket_feed.json',
... Body=json_body)
...
>>> write_to_s3(access_key_id, secret_access_key, '9/1/2017', 'this is a test')
>>>If you go back to your S3 Bucket console you created on the AWS console, you should see a file with the name ‘rocket_feed.json’ and its contents should be like below.
{"date": "9/1/2017", "title": "this is a test"}Compare Last Modified Date Against Stored Date
Let’s retrieve our data from S3. This time we’ll pass in a S3 client instead of defining it in the function.
>>> client = boto3.client('s3',
... aws_access_key_id=access_key_id,
... aws_secret_access_key=secret_access_key)
>>>
>>> def get_s3_obj(client, bucket_name, bucket_file, region):
... body = client.get_object(Bucket=bucket_name, Key=bucket_file)['Body']
... return json.loads(body.read())
...
>>> print(get_s3_obj(client, 'rocketsquirrel', 'rocket_feed.json', 'us-west-2'))
{'date': '9/1/2017', 'title': 'this is a test'}
>>>
Now let’s make a function to compare the date value in S3 and the last-modified header.
We need not convert to any date objects and do a comparison. It is enough to check for inequality.
>>> date = get_s3_obj(client, 'rocketsquirrel', 'rocket_feed.json', 'us-west-2')['date
']
>>> print(date)
9/1/2017
>>>
>>> last_modified = get_last_modified('https://rocketsquirrel.org/feed')
>>> print(last_modified)
Mon, 04 Sep 2017 20:18:49 GMT
>>>
>>> def has_new_posts(date, last_modified):
... if last_modified == date:
... return False
... return True
...
>>> print(has_new_posts(date, last_modified))
True
>>>Retrieve New Posts and Update Date and Title
Now let’s retrieve all new entries when there is new content and update S3 with the latest date and title.
We will put a break statement when we encounter the title which is stored in S3 because that means we hit the previous blog post which we have posted.
We will reverse the urls to keep them in chronological order, first being the oldest blog entry which has not been sent to Slack.
>>> def get_new_posts(client, bucket_name, bucket_file, url, date, title):
... urls = []
... last_modified = get_last_modified(url)
... if has_new_posts(date, last_modified):
... feed = feedparser.parse(url)
... new_title = feed.entries[0].title
... write_to_s3(access_key_id, secret_access_key, last_modified, new_title)
...
... for item in feed.entries:
... if item.title == title:
... break
... post_meta = {'url': item.link}
... urls.append(post_meta)
... urls.reverse()
... return urls
...
>>> bucket_name = 'rocketsquirrel'
>>> bucket_file = 'rocket_feed.json'
>>> date = 'tmp'
>>> title = u'Project Euler with ES6 \u2013 Problem 1'
>>> url = 'https://rocketsquirrel.org/feed'
>>>
>>> print(get_new_posts(client, bucket_name, bucket_file, url, date, title))
[{'url': 'https://rocketsquirrel.org/@jeffliu/javascript/project-euler-es6-problem-2'}
, {'url': 'https://rocketsquirrel.org/@darren/wordpress/simple-way-get-single-posts-ta
xonomy'}]
>>>Now let’s cleanup and refactor the code we have a bit.
We’ll extrapolate S3 clients and other hard coded values and refactor functions.
We’ll add a create bucket function and initialize the json file inside get_s3_obj in case bucket and/or json file has not been created yet.
import boto3
import configparser
import feedparser
import json
import requests
def get_s3_client(access_key_id, secret_access_key):
return boto3.client('s3',
aws_access_key_id=access_key_id,
aws_secret_access_key=secret_access_key)
def create_s3_bucket(client, bucket_name, region):
bucket_names = []
for bucket in client.list_buckets()['Buckets']:
bucket_names.append(bucket['Name'])
if bucket_name not in bucket_names:
region_constraint = {'LocationConstraint': region}
client.create_bucket(ACL='private',
Bucket=bucket,
CreateBucketConfiguration=region_constraint)
def write_to_s3(client, bucket_name, bucket_file, date, title):
body = {'date': date, 'title': title}
json_body = json.dumps(body)
return client.put_object(ACL='private',
Bucket=bucket_name,
Key=bucket_file,
Body=json_body)
def get_s3_obj(client, bucket_name, bucket_file, region):
try:
body = client.get_object(Bucket=bucket_name, Key=bucket_file)['Body']
except:
create_s3_bucket(client, bucket_name, region)
write_to_s3(client, bucket_name, bucket_file, '', '')
body = client.get_object(Bucket=bucket_name, Key=bucket_file)['Body']
return json.loads(body.read())
def get_last_modified(url):
return requests.head(url).headers['Last-Modified']
def has_new_posts(date, last_modified):
if last_modified == date:
return False
return True
def get_new_posts(client, bucket_name, bucket_file, url, date, title):
urls = []
last_modified = get_last_modified(url)
if has_new_posts(date, last_modified):
feed = feedparser.parse(url)
new_title = feed.entries[0].title
write_to_s3(client, bucket_name, bucket_file, last_modified, new_title)
for item in feed.entries:
if item.title == title:
break
post_meta = {'url': item.link}
urls.append(post_meta)
urls.reverse()
return urlsPost to Slack
Setup Your Slack Bot
- Create a test Slack here
- Follow the instructions here and create your Slack Bot here
- Be sure to note the bot’s API Token
- Invite your Slack Bot to the channel(s) you want to post to by going to the channel and doing @<bot name you created> and clicking the invite link
Code
>>> posts = get_new_posts(client, bucket_name, bucket_file, url, date, title)
>>> print(posts)
[{'url': 'https://rocketsquirrel.org/@jeffliu/javascript/project-euler-es6-problem-2'}
, {'url': 'https://rocketsquirrel.org/@darren/wordpress/simple-way-get-single-posts-ta
xonomy'}]
>>>
>>> token = 'yourtoken'
>>>
>>> from slackclient import SlackClient
>>> slack_client = SlackClient(token)
>>>
>>> def post_to_slack(slack_client, posts, slack_channels, slack_blurb):
... for post in posts:
... url = post['url']
... blurb = slack_blurb + url
... for slack_channel in slack_channels.split():
... slack_client.api_call('chat.postMessage',
... channel=slack_channel,
... text=blurb,
... link_names=1,
... as_user='true')
...
>>> post_to_slack(slack_client, posts, '#_general #dotorg', 'New blog post')
>>>When we check our Slack channels, #_general and #dotorg, we’ll see the below.

We’ll refactor a little bit to avoid hard coding. We’ll add a blurb and insert the author and url into it.
slack_blurb = ('A Squirrel by the name of {author} has published a new blog entry. '
'Check it out here! {url}')def transform_blurb(slack_blurb, url, author):
return slack_blurb.replace('{url}', url).replace('{author}', author)
def get_author(url):
at = url.index('@')
end = url.index('/', at)
return url[at:end]
def post_to_slack(slack_client, posts, slack_channels, slack_blurb):
for post in posts:
url = post['url']
author = get_author(url)
blurb = transform_blurb(slack_blurb, url, author)
for slack_channel in slack_channels.split():
slack_client.api_call('chat.postMessage',
channel=slack_channel,
text=blurb,
link_names=1,
as_user='true')Now we’ll externalize the configurations and add a main.
import configparser
import os
def load_config(config_file, config_section):
dir_path = os.path.dirname(os.path.realpath(__file__))
if os.path.isfile(dir_path + '/' + config_file):
config = configparser.ConfigParser()
config.read(config_file)
access_key_id = config.get(config_section, 'access_key_id')
secret_access_key = config.get(config_section, 'secret_access_key')
region = config.get(config_section, 'region')
bucket_name = config.get(config_section, 'bucket_name')
bucket_file = config.get(config_section, 'bucket_file')
slack_token = config.get(config_section, 'token')
slack_channels = config.get(config_section, 'channels')
slack_blurb = config.get(config_section, 'blurb')
url = config.get(config_section, 'url')
else:
access_key_id = os.environ['access_key_id']
secret_access_key = os.environ['secret_access_key']
region = os.environ['region']
bucket_name = os.environ['bucket_name']
bucket_file = os.environ['bucket_file']
slack_token = os.environ['token']
slack_channels = os.environ['channels']
slack_blurb = os.environ['blurb']
url = os.environ['url']
return [access_key_id, secret_access_key, region, bucket_name, bucket_file,
slack_token, slack_channels, slack_blurb, url]
def main():
config_file = 'config.ini'
config_section = 'dev'
(access_key_id,
secret_access_key,
region,
bucket_name,
bucket_file,
slack_token,
slack_channels,
slack_blurb,
url) = load_config(config_file, config_section)
client = get_s3_client(access_key_id, secret_access_key)
json_body = get_s3_obj(client, bucket_name, bucket_file, region)
date = json_body['date']
title = json_body['title']
posts = get_new_posts(client, bucket_name, bucket_file, url, date, title)
print(posts)
slack_client = SlackClient(slack_token)
post_to_slack(slack_client, posts, slack_channels, slack_blurb)
if __name__ == '__main__':
main()Now you can externalize your configs as a config.ini file.
[dev]
ACCESS_KEY_ID: youraccesskeyid
SECRET_ACCESS_KEY: yoursecretaccesskey
REGION: us-west-2
BUCKET_NAME: rocketsquirrel
BUCKET_FILE: feed.json
TOKEN: yourslacktoken
CHANNELS: #dotorg #_general
BLURB: A Squirrel by the name of {author} has published a new blog entry. Check it out here! {url}
URL: https://rocketsquirrel.org/feedOr export them as environment variables. If you go this route, do not have config.ini in your directory as config.ini will take precedence. This portion will be important when we move to AWS Lambda.
export access_key_id = "youraccesskeyid"
export secret_access_key = "yoursecretaccesskey"
export region = "us-west-2"
export bucket_name = "rocketsquirrel"
export bucket_file = "feed.json"
export slack_token = "yourslacktoken"
export slack_channels = "#dotorg #_general"
export slack_blurb = "A Squirrel by the name of {author} has published a new blog entry. Check it out here! {url}"
export url = "https://rocketsquirrel.org/feed"Add an appropriate shebang to the top of your python file.
#!/usr/bin/env pythonAdd execute permissions to your python file, assuming your file is named bot.py
chmod +744 bot.pyNow you can run your python script, assuming your file is named bot.py
./bot.pyYou can run this in a cron on your local or on a host somewhere. In my next post I’ll go over how to set this up on AWS Lambda.

Comments
0
There are currently no comments.
You must be logged in to post a comment.